جدول درهم سازی یا Hash Table چیست؟
جدول درهم سازی (Hash Table) نوعی ساختمان داده است که قادر به نگه داری جفت دادههایی به صورت کلید و مقدار (Key, Value) میباشد. هر کلید در این ساختمان داده مشابه یک فرهنگ لغت به مقدار متناظر خود نگاشت میشود.
تمامی این جفت دادهها در مجموعهای از حفره (Slot) ها یا جام (Bucket) ها با اندیسهای متمایز نگه داری میشوند. ایده پشت پرده این نوع ساختمان داده جستجو و یافتن سریع اندیسی از این مجموعه است که مقدار متناظر با یک کلید مشخص در آن نگه داری میشود. اعمال اصلی که روی یک جدول درهم سازی قابل انجام است عبارتند از:
- جستجوی مقدار مربوط به یک کلید
- افزودن یک جفت کلید و مقدار
- حذف یک جفت کلید و مقدار
درهم سازی و تابع درهم ساز
در جداول درهم سازی، به عمل نگاشت مجموعهای از کلیدها به اندیسهای یک لیست یا آرایه، هش کردن یا درهم سازی (Hashing) گفته میشود. در این ساختمان داده از تابعی به نام تابع درهم ساز (Hash Function) برای محاسبه این اندیس استفاده میشود. به عبارت بهتر تابع درهم ساز برای هر کلید (که به عنوان ورودی دریافت میکند) یک عدد صحیح یا اندیس (به عنوان خروجی) برمیگرداند. حفره متناظر با این اندیس در صورت خالی بودن برای قرار گرفتن مقدار مربوط به آن کلید مورد استفاده قرار میگیرد. توجه داشته باشید که کلیدها در یک جدول درهم سازی باید از یکدیگر متمایز باشند.
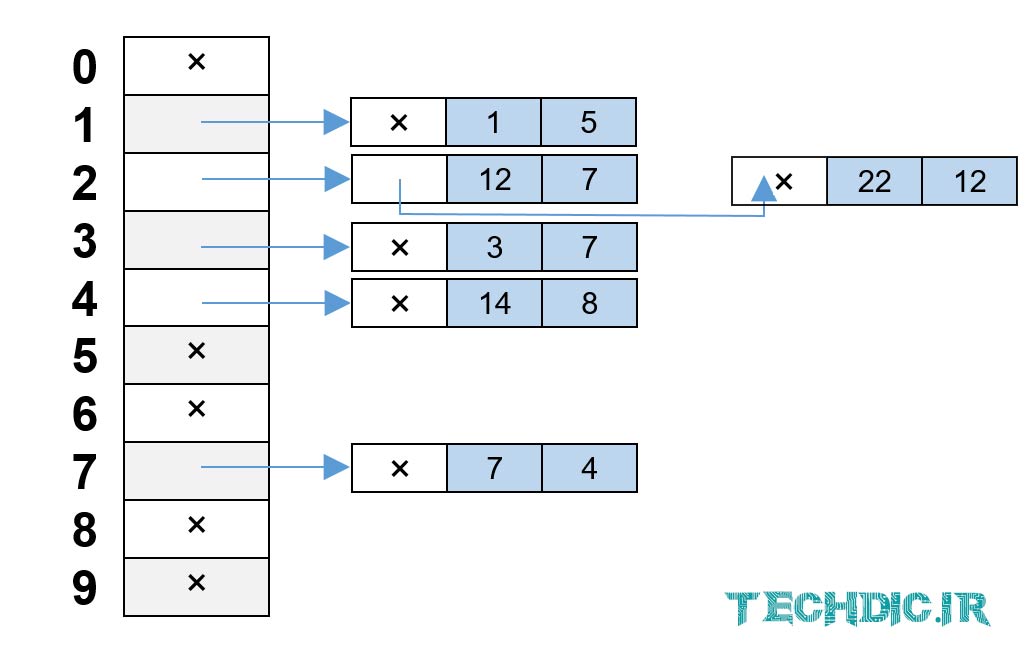
به عنوان مثال فرض کنید جفتهای (Key, Value) به صورت (1, 5)، (3, 7)، (7, 4)، (12, 7) و (14, 8) قرار است در یک جدول درهم سازی که با کمک آرایه معمولی پیاده سازی شده و دارای ظرفیت 10 آیتم (با اندیس های 0 تا 9) است نگه داری شود. تابع درهم ساز را به صورت Key % 10 (یعنی باقیمانده مقدار کلید در تقسیم بر عدد 10) تعریف میکنیم. روشن است که مقدار حاصل از این تابع تنها میتواند یکی از اعداد مابین 0 تا 9 باشد. نتیجه حاصل از تابع درهم ساز برای پنج کلید 1، 3، 7، 12 و 14 همراه با جدول درهم سازی نهایی را میتوانید در تصویر زیر مشاهده کنید. در آرایه حاصل (جدول درهم سازی)، جفت کلید و مقدار هر دو ذخیره شدهاند که البته در این مثال ساده میتوان تنها به ذخیره مقدارها اکتفا نمود:

به منظور جستجو، روندی کاملا مشابه طی میشود. فرض کنید میخواهیم مقدار متناظر با کلید 12 را در جدول فوق بیابیم. این کلید را به تابع درهم ساز میدهیم و تابع، اندیس شماره 2 را برمیگرداند. به این ترتیب مقدار درج شده در حفره دوم جدول یعنی 7 به آسانی و بدون نیاز به بررسی سایر حفرهها یافت میشود.
در حالت ایده آل انتظار داریم تابع درهم ساز، هر کلید را به یک حفره منحصربفرد و متفاوت نگاشت کند. چنین تابعی را تابع درهم ساز پرفکت یا کامل (Perfect Hash Function) مینامند. حال تصور کنید بخواهیم جفت جدید (22, 12) را به جدول درهم سازی فوق اضافه کنیم. با توجه به اینکه باقی مانده 22 بر عدد 10 برابر با 2 میشود بنابراین اندیس 2 توسط تابع درهم ساز برای قرار گرفتن جفت جدید انتخاب میشود. این در حالیست که حفره مربوط به این اندیس در آرایه اشغال میباشد. به این پدیده، برخورد (یا Collision) گفته میشود که در آن اندیسی یکسان برای دو یا چند کلید متفاوت تولید میشود. در چنین مواردی لازم است با کمک روشهای مختلف، اندیس مناسبی برای قرارگیری مقدار مربوط به کلید یا کلیدهای دیگر درنظر گرفته شود.
یکی از مشخصههای مهم جدولهای درهم سازی، فاکتور لود (Load Factor) نام دارد که به صورت “تعداد جفتهایی که قرار است در جدول ذخیره شود تقسیم بر تعداد حفرهها” محاسبه میشود. هرچه این مقدار بزرگتر باشد کارایی جدول درهم سازی پایینتر میآید. البته زمانی که فاکتور لود به سمت صفر میل میکند نیز با اتلاف حافظه روبرو میشویم چرا که در این حالت تعداد حفرهها به مراتب بیشتر از تعداد جفت کلید و مقدار خواهد بود. یک تابع درهم ساز پرفکت که مقادیر حاصل از آن برای n کلید به صورت n عدد صحیح پشت سرهم (معمولا 0 تا n-1) باشد را تابع پرفکت مینیمال مینامند چرا که در این حالت هیچ اتلاف حافظهای نخواهیم داشت.
از جمله کاربردهای رایج جداول درهم سازی در ایجاد آرایه های انجمنی و ایندکس کردن پایگاه داده ها میباشد.
برطرف نمودن برخورد
معمولا بروز برخورد در مواقعی که تعداد زیادی جفت کلید/مقدار در اختیار داریم حتی با استفاده از بهترین توابع درهم ساز نیز غیرقابل اجتناب است. بنابراین وجود یک استراتژی مناسب برای برطرف نمودن برخوردها ضروری میباشد. آدرس دهی باز (Open Addressing) یکی از رایجترین این استراتژیهاست. در این روش اگر اندیسی از آرایه که برای قرارگیری موجودیت جدید انتخاب شده اشغال باشد با استفاده از یک روش کاوش، به دنبال حفره دیگری میگردیم که خالی باشد. برای مثال در مدل کاوش خطی (Linear Probing) اگر حفرهای پر باشد تک تک حفرههای پس از آن را تا زمانی که مکان خالی پیدا شود کاوش میکنیم. درنتیجه برای افزودن جفت (22, 12) در جدول فوق ابتدا حفره 2 بررسی میشود. از آنجایی که این حفره اشغال است به سراغ حفره 3 میرویم. این کار به همین ترتیب ادامه مییابد تا نهایتا جفت (22, 12) در حفره 5 قرار میگیرد. هنگام جستجو برای یافتن مقدار متناظر با کلید 22 نیز ابتدا حفره 2 بررسی میشود و این بررسی تا رسیدن به حفرهای که کلید 22 در آن ذخیره شده است ادامه مییابد. گفتنی است طول گامها در کاوش خطی میتواند مقدار ثابتی به جز یک هم داشته باشد. درهم سازی دوبل (Double Hashing) این طول گام را براساس یک تابع درهم ساز ثانویه محاسبه میکند.
زنجیره سازی مستقل (Separate Chaining) نمونهای دیگر از استراتژیهای رفع برخورد است که در آن هر حفره به یک لیست مجزا اشاره میکند. هر لیست تمامی جفت های کلید و مقداری که در اندیس مربوط به آن حفره دچار برخورد میشوند را در خود نگه داری میکند. برای پیاده سازی لیستها معمولا از لیستهای پیوندی استفاده میشود. در تصویر زیر نحوه ایجاد جدول درهم سازی با کمک این استراتژی و پس از افزودن جفت (22, 12) نمایش داده شده است. در این روش، هنگام جستجو برای مقدار متناظر با کلید 22 تنها کافی است لیست مربوط به حفره 2 مورد کاوش قرار گیرد.
پیوندهای پیشنهادی تک دیک